Harness Engineering
今年以来这个Harness Engineering这个词的热度很高,最近公司一直在推AI辅助编程,所以就花了几天时间学习了下这个东西。harness这个词不是一个软件框架(比如orm的mybatis),它是一种开发的新范式,可以理解是一种指导思想、一种开发规范,本质是用来提升大模型的使用效果。
https://openai.com/index/harness-engineering/
这篇文章提出了Humans steer. Agents execute的观点。
开发人员主要关注以下:
systems(通过prompt进行系统功能、任务描述)
scaffolding(脚手架设计,像架构分层及层级单向调度)
leverage(好多地方翻译为杠杆,我认为的是影响力,对agent自动执行流程施加影响,按prompt交互运行)。
Harness Engineering这种工程范式体现在以下几个方面:
1、提高程序的可读性(Increasing application legibility):采取了各种辅助手段(application UI, logs, and app metrics),增强agent能读取程序的能力。
2、统一以知识库作为标准信息来源(We made repository knowledge the system of record):消除庞大的指导规则约束文档,采用渐进式披露的方式,维护规约目录文件。
为什么要放弃庞杂巨大的指导规约文档:
Context is a scarce resource:我们知道模型上下文有限制,如果太庞大了,加载到模型context里面,会导致其他关键信息的排挤。
Too much guidance becomes non-guidance:一切都很重要的时候其实就都不重要了。
It rots instantly:如果没有实时更新机制,里面就会慢慢积累错误的、过时的信息。
It’s hard to verify:超大文件无法自动化校验无法即时更新就会导致数据偏颇。
3、agent的阅读理解力是目标(Agent legibility is the goal):让agent能够直接从代码、工件推理出完整的业务领域。维护好代码库、已版本化的工件(code, markdown, schemas, executable plans)
4、统一架构规范和设计格调(Enforcing architecture and taste):agent在具有严格边界和可预测结构的环境中最为高效,所以应用尽可能的分层设计且单向调用约束,这些约束可以通过代码检查器和结构测试来强制实现(比如额外启用另外两个agent分职责校验)
5、agent自治(agent-generated):开发人员以跟过去不一样的形式存在于agent研发流程中,对工作进行优先排序,将用户反馈转化为可接受标准,并验证产出。发现agent遇到异常时,确认缺失的tools、guardrails、documentation,反馈到代码库,让agent自我修复。
6、混乱情景和垃圾回收(Entropy and garbage collection):随着需求的迭代,会产生很多无效代码、过时废弃方案等工件,built a recurring cleanup process进行了类似垃圾回收的操作。
https://www.anthropic.com/engineering/harness-design-long-running-apps
这篇文章主要侧重于多agent协同工作是Harness Engineering的范畴
大语言模型存在两大核心问题:
1、上下文偏移问题:当上下文长度增加时,模型输出会偏离预设目标,在接近上下文长度极限时还会提前结束任务,目前采用Context resets方案缓解,但会增加编排复杂度、令牌开销和运行延迟;
2、评价偏差问题:模型对自身输出的评价偏向正面,无法保持客观,可通过基于不同大语言模型构建评估器解决。
先通过前端设计案例构建了双agent架构:生成智能体(Generator agent)负责实现设计,评估智能体(Evaluator agent)对输出进行评审打分,通过「评审-开发-再评审-再开发」的循环迭代优化输出质量;之后演进为多agent协同分工模式,新增规划智能体(Planner agent)负责产品上下文梳理与高级技术规范制定,生成智能体(Generator agent)逐个实现规范功能,评估智能体(evaluator agent)负责输出评估,各智能体之间通过文件完成通信。文中还补充提及了数字音频工作站的案例来验证思路。
https://www.langchain.com/blog/the-anatomy-of-an-agent-harness
这篇文章对harness和model以及agent做了关联定义:
Agent = Model + Harness(蓝色是模型,外围一切都是harness)
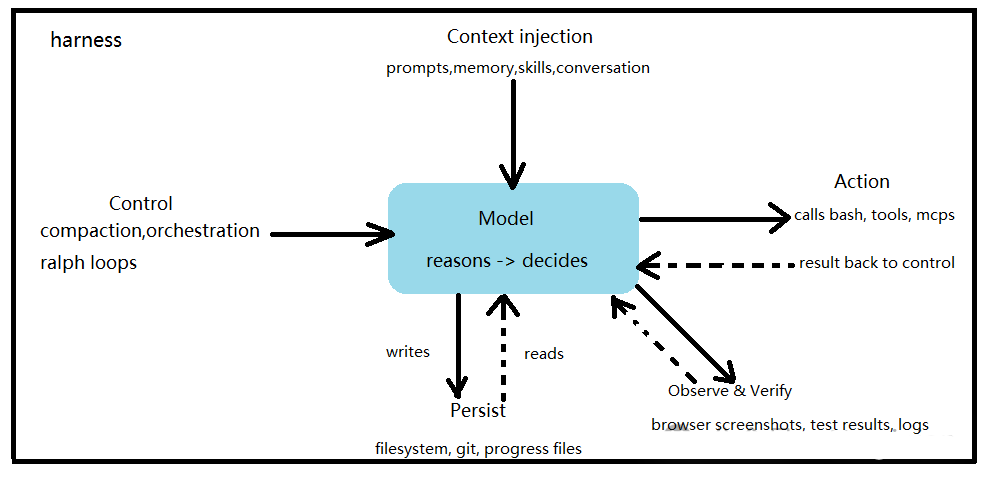
Harness Engineering:就是围绕模型构建系统,把模型变成能干活的引擎。模型提供智能,Harness让智能变得有用
harness包括:
系统提示词(System Prompts)
Tools、Skills、MCP 协议及其描述
打包的基础设施(filesystem, sandbox, browser)
编排逻辑(subagent spawning, handoffs, model routing)
确定性执行的钩子 / 中间件(compaction, continuation, lint checks)
harness的实现方式及赋能:
文件系统持久存储与上下文管理:让agent能持久存储、操作真实数据、把放不下的上下文 “卸出去”、跨会话持续工作;Git 再给文件系统加上版本:跟踪进度、回滚错误、分支实验
Bash + 代码作为通用执行工具:让agent能自主解决问题,给harness带上Bash工具,让模型能通过写代码、执行代码来自主解决问题。
沙箱和工具执行与工作验证:Sandboxes给agent提供安全的运行环境,让它能安全行动、观察结果、持续推进。
记忆与搜索实现持续学习:让agent通过Memory能记住见过的信息、通过search访问训练截止后新增的知识,实现持续学习能力。
对抗 “上下文腐烂”:agent性能不要随着工作推进而变差,通过Compaction、Tool Call Offloading、Progressive Disclosure等方法和机制实现高质量上下文工程。
长周期自治执行:让agent能跨长时间周期、自主、正确地完成复杂工作。文件系统 + Git:跨会话跟踪工作;Ralph 循环:强制继续工作;规划 + 自验证:保持方向。
harness这个东西其实不复杂,比如用到了Skill和MCP这些就是harness范畴的东西;我们在通过SDD模式进行开发的时候,你助openSpec或者superpowers生成的proposal.md,plan.md,design.md等md文档都是为了加强模型的产出,这些也是harness范畴;我们为了让AI辅助编程进行的更贴合人类意愿,会用prompt设定AI职责,让它对整个project的层级(api、dao、service、web等,以及各层级职责描述)熟悉,并且把开发规则习惯输出到project的根目录,要求后续AI编程必须借鉴这个规则,那么这也是harness范畴;后续可以在SDD规范下,创建多智能体协同工作机制,就像采用上述的Planner+Generator+Evaluator多智能体协同工作,把harness能力充分挖掘出来助力AI开发。