复盘|「天池 X LeetCode」在线编程专场选拔赛
复盘|「天池 X LeetCode」在线编程专场选拔赛统计链表奇数节点【一次遍历】遍历即可,小技巧是ans直接加0/1结果,省去if判断这一步。
1234567class Solution: def numberEvenListNode(self, head: Optional[ListNod
...
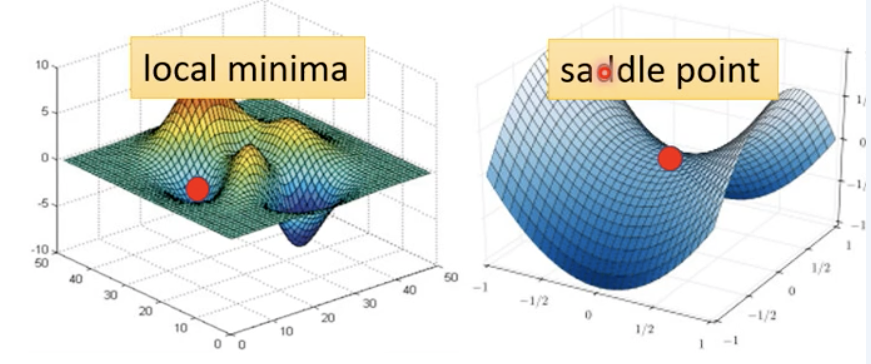
神经网络中,Gradient为0(或不存在)的点称为临界点(critical point),其有两种可能性:局部极小(local minima)和鞍点(saddle point)。
长期以来,人们普遍认为,神经网络优化问题困难是因为较大的神经网络中包含很多局部极小值,使得算法容易陷入到其中某些点。2014年的一篇论文中提出高维非凸优化问题之所以困难,是因为存在大量的鞍点而不是局部极值。
鞍点:
- 一个维度向上倾斜且另一维度向下倾斜的点。这些鞍点通常被相同误差值的平面所包围,这使得算法陷入其中很难脱离出来,因为梯度在所有维度上接近于零
- 梯度等于零,在其附近Hessian矩阵有正的和负的特征值,行列式小于0,即是不定的。
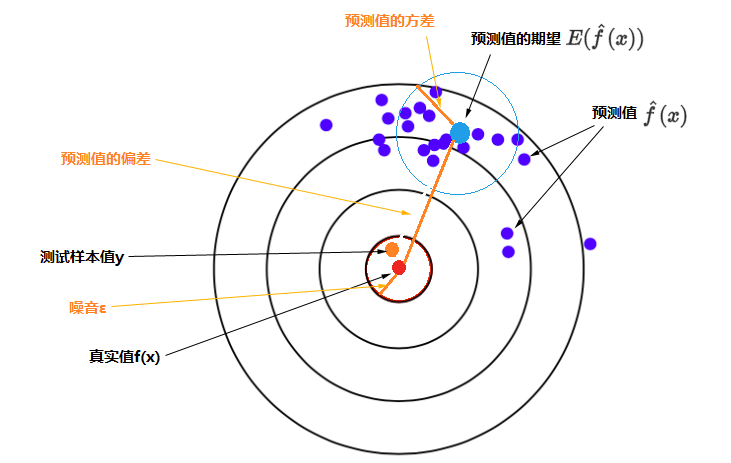
使用样本数据拟合函数,由于样本数据使采样而并非真实值本身,采样本身会带来误差。经过研究发现,其误差的期望值可以分解为三个部分:样本噪音、模型预测值的方差、预测值相对真实值的偏差,公式为:
$$
E\left((y-\hat{f}(x))^{2}\right)=\sigma^{2}+\operatorname{Var}[\hat{f}(x)]+(\operatorname{Bias}[\hat{f}(x)])^{2}
$$
其中$Bias[\hat{f}(x)] = E[\hat{f}(x) - f(x)]$,即误差的期望值 = 噪音的方差 + 模型预测值的方差 + 预测值相对真实值的偏差的平方,如下图所示。
回归大致可以理解为根据数据集$D$,拟合出近似的曲线,所以回归也常称为拟合(Fit)。按照自变量的数量可以分为一元回归和多元回归,按照自变量与因变量之间的函数表达式可以分为线性回归(Linear Regression)和非线性回归(Non-linear Regression)。
多元线性模型就是特征x的线性组合的函数,可以表示为$y=\sum{w_ix_i}+b$,$x_i$为特征,$w_i$为权重,b为偏移量。
机器学习是人工智能的一部分, 研究如何让计算机从数据学习某种规律。机器学习的目的是通过计算机程序根据数据去优化某一个评价指标,自动的从数据发现规律, 使用这些规律做出预测。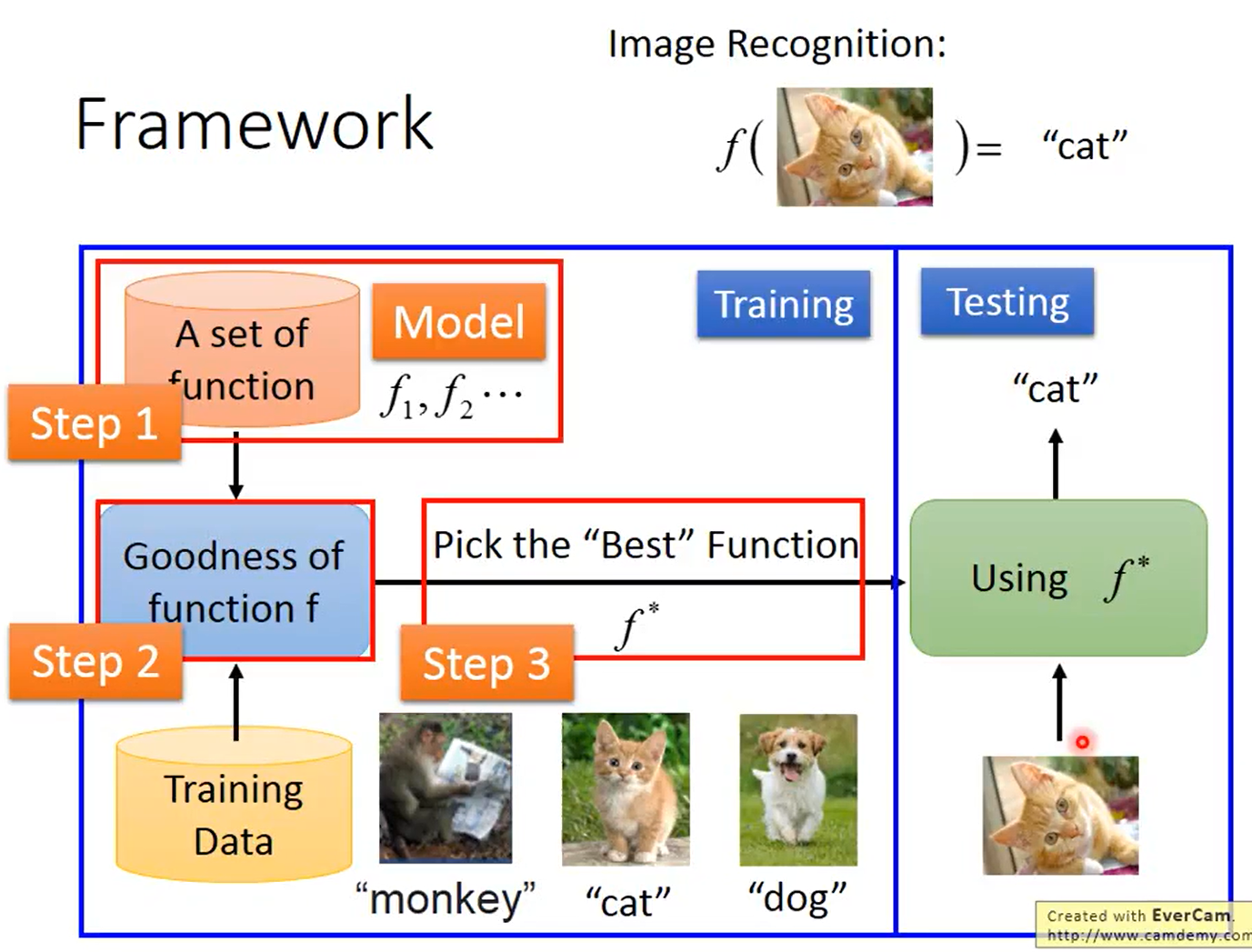
如图,机器学习可以简化为三个步骤,一、找一个function,二、让machine评价这个function,三、让machine自动地挑出最好的function。
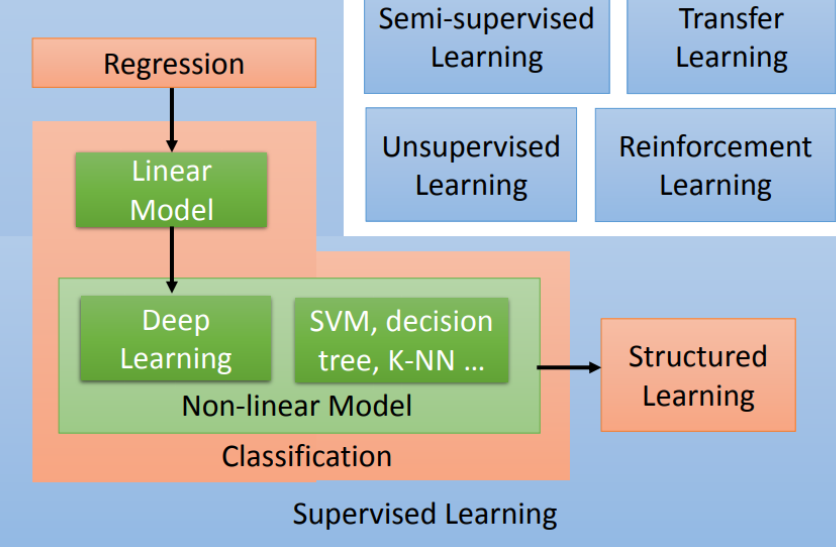
机器学习可大致分为监督学习、无监督学习、半监督学习、迁移学习和强化学习。
监督学习是机器学习任务的一种。它从有标签的训练数据中推导出预测函数。有标签的训练数据是指每个训练实例都包括输入和期望的输出。简单来说就是给定数据,预测标签。
监督学习包括分类和回归。
当数据集规模超级大时,很难有足够大的内存完全存下所有数据。因此需要一个按需加载样本到内存的数据集类。
Dataset基类Dataset基类介绍在PyG中,通过继承torch_geometric.data.Dataset基类来自定义一个按需加载样本到内存的数据集类。
继承此基类相比较继承torch_geometric.data.InMemoryDataset基类要多实现以下方法:
len():返回数据集中的样本的数量。get():实现加载单个图的操作。注意:在内部,getitem()返回通过调用get()来获取Data对象,并根据transform参数对它们进行选择性转换。图表征学习要求在输入节点属性、边和边的属性(如果有的话)得到一个向量作为图的表征,基于图表征进一步的我们可以做图的预测,而图同构网络(Graph Isomorphism Network, GIN)的图表征网络是当前最经典的图表征学习网络。
GNN的目标是以图结构数据和节点特征作为输入,以学习到节点(或图)的embedding,用于分类任务。
基于邻域聚合的GNN可以拆分为以下三个模块:
但是Aggregate的三种方式sum、mean、max的表征能力不够强大。
图卷积网络(GCN)已经成功地应用于许多基于图形的应用,然而大规模的GCN的训练仍然具有挑战性。目前基于SGD的算法要么面临着随GCN层数呈指数增长的高计算成本,要么面临着保存整个图形和每个节点的embedding到内存的巨大空间(显存)需求。于是论文Cluster-GCN: An Efficient Algorithm for Training Deep and Large Graph Convolutional Network提出了Cluster-GCN方法来解决超大图的训练问题。