异常检测顾名思义就是检测出与正常数据不同的数据,检测给定的新数据是否属于这组数据集。
1. 异常检测的任务类型
无监督:训练集无标签
有监督:训练集的正例和反例均有标签
半监督:在训练集中只有正例,异常实例不参与训练
2. 异常检测的难点
数据量少:异常检测任务通常情况下负样本(abnormal)较少,0、1两类样本严重不均衡,有时候依赖于人工标签。
噪音:异常和噪音有时容易混淆,如两幅图中的A点识别难度就不一样。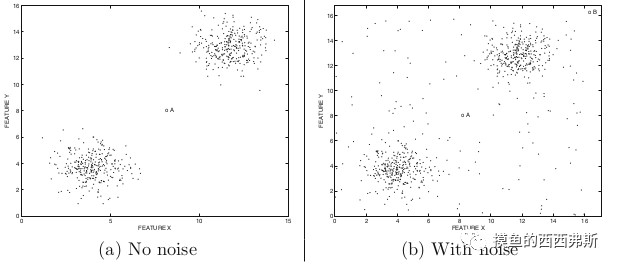
3. 异常检测方法简介
3.1 基于统计学的方法
通常做法是假设样本服从高斯分布,计算p(x)=ϵ作为判定正常和异常的阈值。
3.2 线性模型
在线性模型中,有2个假设:
①不同维度的变量近似线性相关,可以通过一个相关系数矩阵进行衡量。
②数据是镶嵌在低维子空间中的,线性建模是为了找到某个低维子空间使异常点区别于正常点。
常用模型的包括:
最小二乘法——最小化目标函数得到直线方程,计算每个变量与回归方程之间的残差,可通过3σ 法则判断异常值.
PCA——将样本的协方差矩阵特征值分解后,特征值是样本投影到轴上对应的方差,特征值越小,投影后样本点分布越集中,异常点容易偏离,以此作为判定异常值的一个指标。
3.3 基于邻近度的方法
这类算法适用于数据点的聚集程度高、离群点较少的情况,不适用于数据量大、维度高的数据。
①基于集群(簇)的检测——DBSCAN,核心点距离ℇ内最小包含点数、距离ℇ与阈值比较。
②基于距离的度量——KNN,将K-近邻距离与阈值比较。
③基于密度的度量——LOF(局部离群因子),邻域点密度与阈值比较。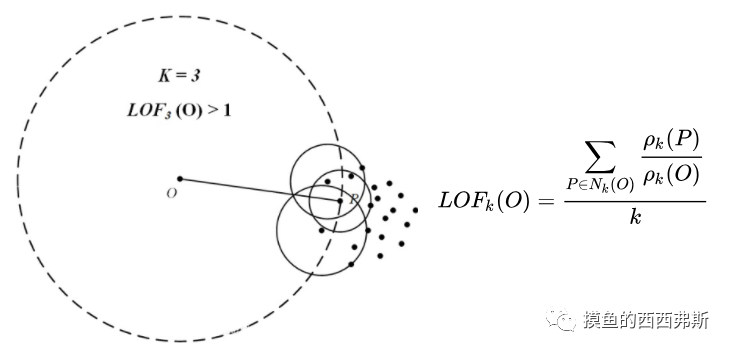
3.4 集成方法
①孤立森林(Isolation Forest)——不停地使用随机超平面分隔每个子空间,直到每个子空间只有一个数据点为止,低密度的点被单独分配到一个子空间,孤立数低于阈值时,定义为异常值。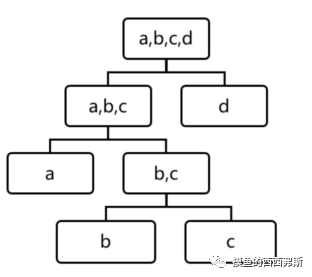
②树模型——通过树不断划分子空间,数据点在多个树上的平均深度越浅,越可能为异常值。
